VAL-9000
A self-hosted AI assistant stack running entirely on local hardware — LLM inference, text-to-speech, and physical hardware interfaces, all without a single cloud API call.
- GPU-accelerated local LLM inference (Ollama + Llama 3)
- Text-to-speech via Kokoro TTS
- Multi-source ingestion pipeline — web pages, YouTube, git repos, local files
- FastAPI coordinator server orchestrating all services and hardware I/O
- Physical interfaces: MECHROPAD for input, VAL-EYE for visual output
- Fully containerized via Docker Compose
Details
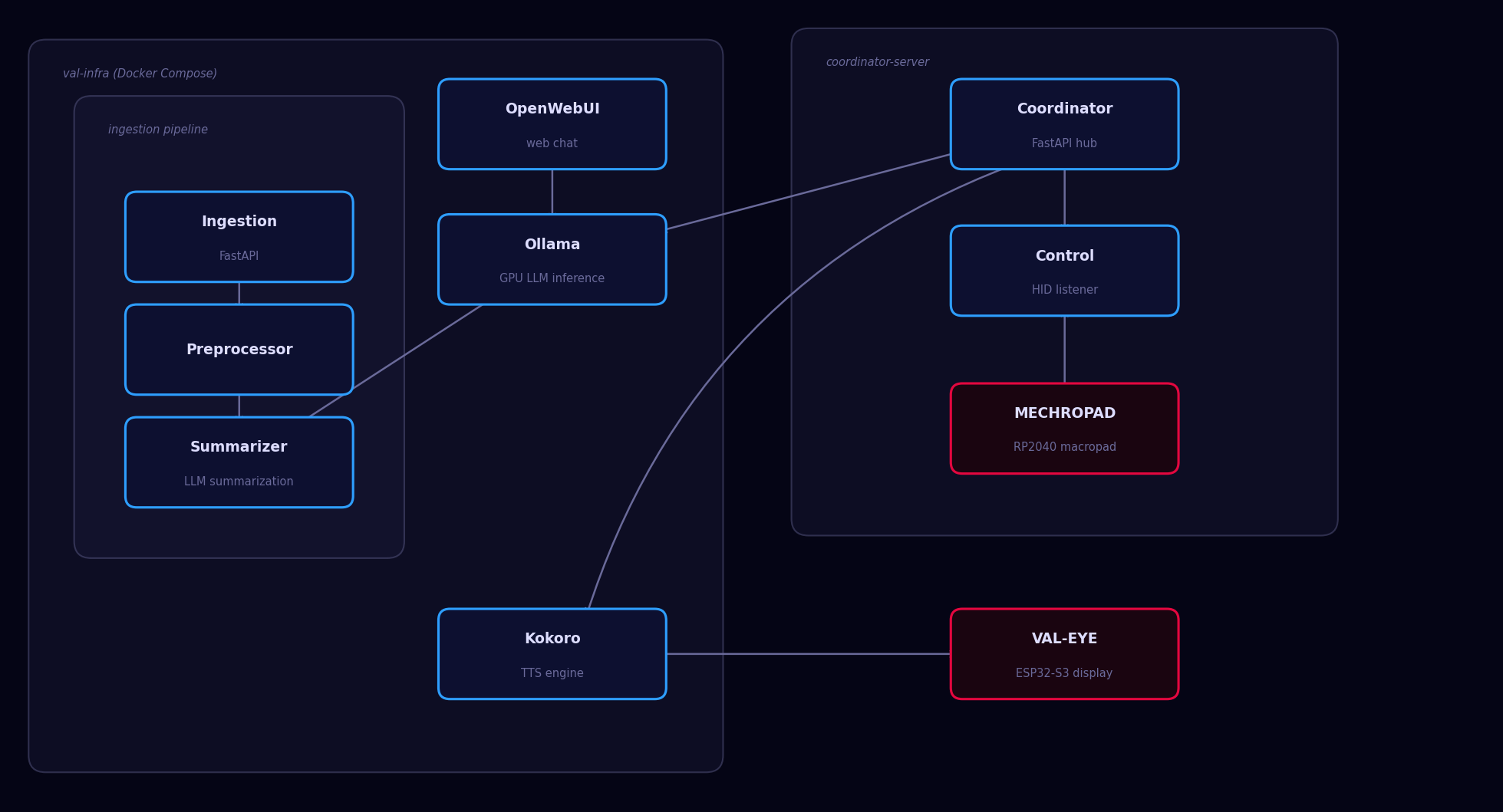
Stack
All services run containerized via Docker Compose on local hardware with NVIDIA GPU passthrough:
- Ollama — GPU-accelerated local LLM inference (Llama 3)
- Kokoro — local text-to-speech synthesis
- OpenWebUI — web-based chat interface
- Ingestion service — custom FastAPI service for feeding RAG content
- Preprocessor — cleans and prepares ingested content for retrieval
Custom Personality
VAL-9000 runs a hand-authored Modelfile defining a consistent personality with Big Five and MBTI trait scores, a defined value system, and specific behavioral constraints. The result is a coherent assistant character that remains consistent across sessions rather than a generic chatbot.
RAG Ingestion Pipeline
A FastAPI ingestion service accepts content from multiple source types and normalizes it into RAG-ready text:
- Web pages (main content extraction)
- YouTube videos (transcript ingestion)
- Git repositories
- Local files
Hardware Interface
The physical presence is VAL-EYE — an ESP32-S3 with a 240x240 circular display running a real-time software-rasterized 3D scene that reacts to VAL-9000's audio output, changing visual state based on whether the assistant is idle or speaking.